对于给定 f , 试图寻找它的最小值 x∗=argminf(x)
梯度下降法 给出了一种寻找局部最小值的方法:
xn=xn−1−η⋅∇f
其中 η 就是学习率。那么 η 的取值范围是多少的情况下,梯度下降算法可以收敛呢?
显然, η 总可以取得非常小以至于可以收敛。所以我们主要关心它的上界。由于函数性质的不同,上界差异较大。这里介绍最简单的一种情形:当 f 满足 Lipschitz光滑 时。
L− 光滑:对于任意的 (x,y)
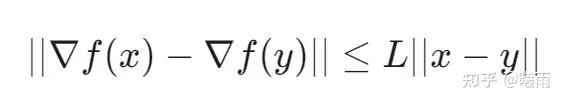
为了避免过于复杂的矩阵微分,这里我们暂时将其视作一元微分进行说明。在 f 二阶可微的情况下,上述条件可以被等价地表述为 ∇2f≤L
考虑 f(xn+1)−f(xn)
根据 拉格朗日余项 (取到二阶) ,在 xn 处
f(xn+1)−f(xn)≤∇f(xn)(xn+1−xn)+2L(xn+1−xn)2
代入 xn+1=xn−η⋅∇f 可得
f(xn+1)−f(xn)≤η(ηL/2−1)(∇f(xn))2
目标是让后者小于零,所以一定有 η≤2/L
实际上还可以优化到 1/L , 见
https://blog.csdn.net/qq_34758157/article/details/132211025blog.csdn.net/qq_34758157/article/details/132211025
神奇的大学习率:多大才算大,神奇的效用又为何? 这篇文章介绍了 1/L 和 2/L 之间的神奇区别。
对于一些简单函数而言,L是很好求的,例如二次函数:
f(x)=ax2+bx+c
它的 二阶导 等于 2a ,因此 L=2a 。这里可能有人会注意到如果 a<0 , L 好像就可以随便取了。确实如此!但是求出来的解没有意义—— a<0 时这是一个凹函数,梯度下降只会一路狂奔到无穷小。